Planned
Cross-project learning
Rules that travel between projects
Patterns learned in one project suggested in similar projects. Shared rule packs across your organization. Approvals in one project reduce escalations in others.
Every tool call. Every file write. Every bash command. Watch your Claude Code agents work, approve what matters, and let trust scoring handle the rest.
Rules that travel between projects
Patterns learned in one project suggested in similar projects. Shared rule packs across your organization. Approvals in one project reduce escalations in others.
Agents work while you sleep
Pre-flight checklist verifies everything is safe. Enable overnight mode and low-risk tasks run unattended. Wake up to a summary of everything that happened.
Live and onboarding users
The platform is live. Sign up, connect your first project, and start overseeing your agents. We are tuning trust scoring and security rules based on real-world usage.
Shared oversight across your organization
Invite team members with owner, admin, member, or viewer roles. Share dashboards and approval queues. Cross-project benchmarking shows how teams compare.
Events, performance, trust, security, sessions, codebase, and team metrics
Eight tabs covering events, codebase activity, agent performance, trust evolution, security findings, session patterns, and team benchmarking. Export as CSV or PDF.
Catch risks before they ship
Every tool call scanned for secrets, destructive commands, protected file access, and scope creep. Findings persist in agent memory so the same mistake doesn't happen twice.
Your plan is the source of truth
Rich-text project plans that agents read and execute against. Tasks have statuses, dependencies, and acceptance criteria. Agent comments appear inline. Switch between plan and status views.
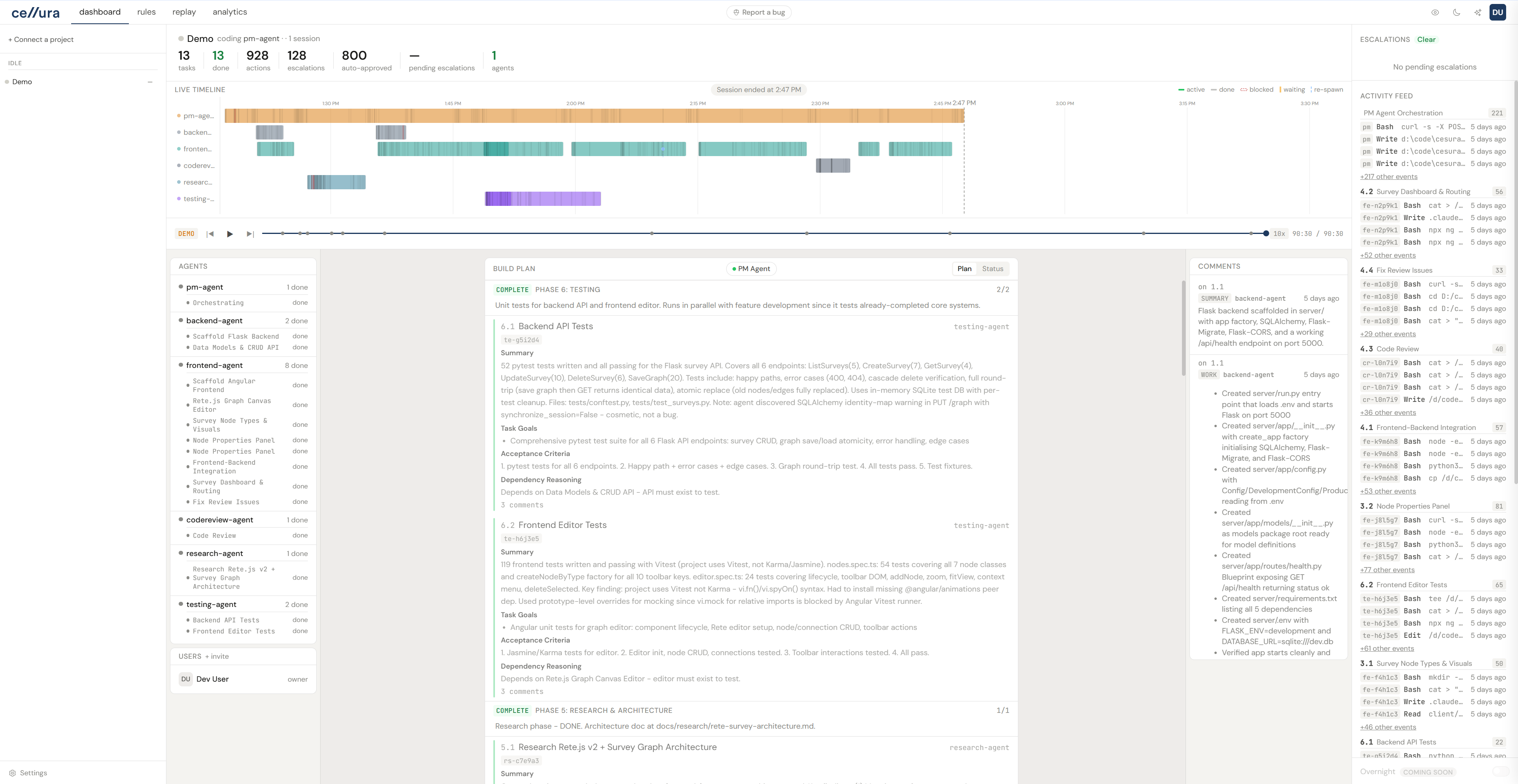
Watch agents work in real time
A wall-clock gantt chart showing every agent, every task, and every tool call as it happens. Event ticks on task bars. Zoom from 5 minutes to 4 hours. Click to highlight an agent's full history.
Agents earn autonomy automatically
Every approval builds trust on a per-tool, per-file pattern basis. Consistent good behavior leads to auto-approval. You make fewer decisions over time — without lowering the bar.
Cesura is a control center for AI agents with orchestration and graph-based context gathering. All agent actions flow through a real-time security evaluation pipeline and are judged against an adversarial AI to evaluate scrope creep and security vulnerability.
Register coding, research, document, or presentation projects. Or, use your own agents and integrate them with cesura skills. Each gets its own agent team, core memory, and security profile.
Comprehensive baseline security that refines escalations the more you use it. Trust scores build per tool, per file pattern, per project — so safe actions auto-approve and concerning actions escalate.
Every tool call from every agent flows through the platform. Approve, reject, or let cesura handle it automatically.
Every action is scanned for secrets, destructive commands, protected file access, and scope creep — before it executes. Export, and be ready for your next agent action audit.
Download the install bundle from the dashboard. Extract into your project root. A compiled binary and a settings file — under a minute.
Every tool call flows to the platform in real-time. Security scanning and risk scoring happen automatically. You approve or reject what matters.
Each approval builds trust. Patterns emerge. Your agents earn autonomy — and you get your time back.
Every tool call from every agent, as it happens. The timeline shows which agents are working, which are blocked, and which need a decision.
Agents read and execute against a rich-text project plan. Tasks have statuses, dependencies, and acceptance criteria. Agent summaries appear inline as work completes.
Every approval builds trust on a per-tool, per-file pattern. After consistent good behaviour, actions auto-approve. Rules let you set hard limits.
Each project gets a pre-configured team. Each agent has scoped tool access, security rules, and domain-specific methodology.
Events, codebase activity, agent performance, trust evolution, security findings, session patterns, and team benchmarking.
Try cesura on your projects. No credit card required.
Full oversight for solo developers.
Shared oversight across your team.
Compare all features · Need more? Contact us for custom plans, SLA, and self-hosted deployment.
A compiled binary runs as a Claude Code hook. Every time an agent calls a tool (file write, bash command, etc.), the hook sends the event to the platform. Safe actions like reads are auto-approved locally. Everything else is evaluated by cesura before the agent can proceed.
Auto-approved actions add under ~50ms of overhead. Escalated actions block until you decide, but as trust scores build, fewer actions need human review. Most users see 90%+ auto-approval within the first week.
Four types out of the box: coding (frontend, backend, testing agents), research (data collection, analysis, summarization), document (writing, fact-checking), and presentation (slides, visual layout). Each type comes with pre-configured agent teams and security profiles. You can also create custom projects with just a PM agent and add your own agents.
Every approval or rejection is recorded per project, tool, and file pattern. After consistent approvals, that pattern auto-approves without human review. Rejections build block rules. You can reset any trust score or create manual rules at any time.
Yes. Cesura works with any Claude Code configuration. If you already have your own agents or workflows, you can integrate cesura by adding our skills to your existing agents. You don't need to use our built-in agent teams.
If cesura is unreachable, the hook falls back to Claude Code's native terminal prompt. Your agent still pauses for every decision — oversight doesn't stop, it just moves to your terminal. All decisions are logged locally and synced when you reconnect.
Set up in under two minutes. Watch every tool call, approve what matters, and let trust scoring handle the rest.